【GAS】getContentTextの使い方
Google Apps Script(GAS)でスクレイピングを実施する際、Webサイトから取得した情報を加工や成形するためにテキスト化する必要がありますが、その際に使われるのがgetContentTextメソッドです。
この記事では、特定ページ情報からgetContentTextメソッドを使いテキストを取得する方法を解説します。
getContentTextメソッドの使い方
getContentTextメソッドの記述方法
UrlFetchApp.fetch([url]).getContentText([文字コード])
getContentTextメソッドはHTTP レスポンスに対して使用し、String型のデータを返します。
GASスクレイピングではUrlFetchApp.fetchメソッド使うことが大半ですが、UrlFetchApp.fetchメソッドはHTTPレスポンスを返すので、続けてgetContentTextを記述をすればWebページのテキストを取得できます。
サンプルコードを記載します。
※サイトによってはスクレイピングを禁止しているので規約をご確認ください
function Scraping() {
const url = "https://cookpad.com/recipe/7047233"; // スクレイピング対象ページのURL
const content = UrlFetchApp.fetch(url).getContentText('UTF-8');
console.log(content);
}Logging output too large. Truncating output. <!DOCTYPE html>
<html lang='ja'>
<head>
<meta charset='utf-8'>
<meta content='IE=edge' http-equiv='X-UA-Compatible'>
<link href='https://cookpad.com/recipe/7047233' rel='canonical'>
<link href='http://m.cookpad.com/recipe/7047233' media='handheld' rel='alternate' type='text/html'>
<link href='https://assets.cpcdn.com/assets/device/apple-touch-icon.png?92b8bd477aedd34713e3d853583626f4d29101bdc7e6ceb52dcfe037b49e0988' rel='apple-touch-icon'>
<link href='/osd.xml' rel='search' title='クックパッド レシピ' type='application/opensearchdescription+xml'>
<title>簡単!美味しい!伊達巻 by りんごキッチン☆ 【クックパッド】 簡単おいしいみんなのレシピが362万品</title><meta content="簡単!美味しい!伊達巻,■はんぺん,■砂糖,■みりん,■日本酒,■しょうゆ,
・・・取得できていそうですね。
getContentTextを使う理由
UrlFetchApp.fetch(url)はHTTPリクエストに対するレスポンスで、HTMLテキスト情報を取得して分析するには、getContentText('文字コード’) で読み取り可能な形に変えるステップが必要です。
文字コードはデフォルトは「utf-8」なので、何も記載しなくても問題ありません。
const content = UrlFetchApp.fetch(url).getContentText('UTF-8'); //getContentText('shift-jis')も記述可能 ちなみに、UrlFetchApp.fetch(url)までの記述でconsole.logしようとすると下記のようなアウトプットになります。
const response = UrlFetchApp.fetch(url);
console.log(response);{ toString: [Function],
getResponseCode: [Function],
getContent: [Function],
getHeaders: [Function],
getContentText: [Function],
getAllHeaders: [Function],
getAs: [Function],
getBlob: [Function] }気になる方はgetContentText以外ではどのようなデータを取得できているのか試してみてください。
UrlFetchApp.fetchの使い方は下記の記事でも詳しく解説しています。

 https://tetsuooo.net/archives/604
https://tetsuooo.net/archives/604getContentTextで取得したテキストの分析方法
Parserライブラリを使用して分析
テキストデータの取得自体はgetContentTextメソッドを使って完了ですが、さらにそのテキストを分析する形に成形するには、Parserライブラリを使います。
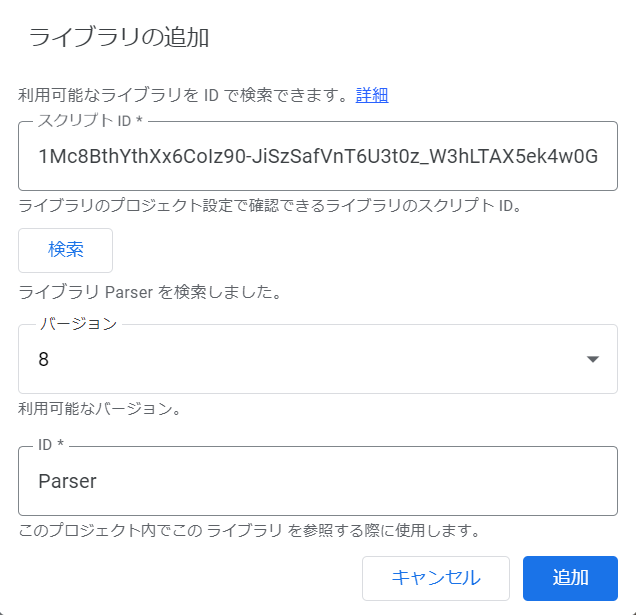
利用するにはエディタ左部の「ライブラリ」の「+」ボタンをクリックして、ポップアップ出ててきたボックスの「スクリプトID」欄にParserライブラリのIDを入力、「追加」ボタンを押せば完了です。
2021年12月現在は下記のIDでした。アップデートで変更になるので最新のIDを調べて入力してみてください。
1Mc8BthYthXx6CoIz90-JiSzSafVnT6U3t0z_W3hLTAX5ek4w0G_EIrNw
Parserライブラリは下記の記事で詳しく解説しています。

サイト上のhtml記述内容を確認
スクレイピングする際は通常何かしらの分析目的等を持っており、取得したいのはページの一部の記述のみである場合が多いです。
Parserライブラリを使って分析するときはMTMLの記述に従ってコードを書いていくので、まずは対象となるパートがどのような記述なのか確認しましょう。
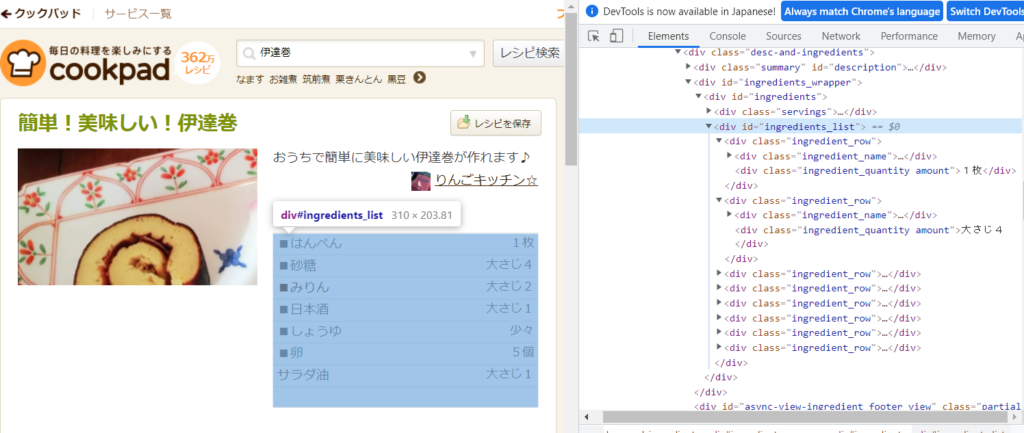
今回スクレイピングを実行した伊達巻レシピの中で材料のブロックのみを抽出したいとします。
MTMLを見ると、このブロックは<div id="ingredients_list">~</div>という記述になっているようです。
開始(from)と終了位置(to)を指定してテキストを抽出
Parser.data(contentText).from('開始位置’).to('終了位置’)で抽出テキストを指定します。
上述のとおり、抜き出したのは「<div id="ingredients_list">で始まって、この<div>ブロックが閉じる</div>まで」のテキストですが、ブロック内で</div>が何度か登場してうまく指定ができないため、<div class="desc-and-ingredients"> に続いて登場する<div id="async-view-ingredient_footer_view">を終了位置とすることで抽出対象を定めたいと思います。
function Scraping() {
const url = "https://cookpad.com/recipe/7047233"; // ページのURL
const contentText = UrlFetchApp.fetch(url).getContentText('utf-8');
const list = Parser.data(contentText).from('<div id=\'ingredients_list\'>').to('<div id=\'async-view-ingredient_footer_view').build();
console.log(list);
}※エスケープを使った記述になっています
<div class='ingredient_row'>
<div class='ingredient_name'><span class='name'>■はんぺん</span></div>
<div class='ingredient_quantity amount'>1枚</div>
</div>
<div class='ingredient_row'>
<div class='ingredient_name'><span class='name'>■砂糖</span></div>
<div class='ingredient_quantity amount'>大さじ4</div>
</div>
<div class='ingredient_row'>
<div class='ingredient_name'><span class='name'><a class="cookdict_ingredient_link" href="/cooking_basics/search/%E3%81%BF%E3%82%8A%E3%82%93">■みりん</a>
</span></div>
<div class='ingredient_quantity amount'>大さじ2</div>
</div>
<div class='ingredient_row'>
<div class='ingredient_name'><span class='name'>■日本酒</span></div>
<div class='ingredient_quantity amount'>大さじ1</div>
</div>
<div class='ingredient_row'>
<div class='ingredient_name'><span class='name'>■しょうゆ</span></div>
<div class='ingredient_quantity amount'>少々</div>
</div>
<div class='ingredient_row'>
<div class='ingredient_name'><span class='name'>■卵</span></div>
<div class='ingredient_quantity amount'>5個</div>
</div>
<div class='ingredient_row'>
<div class='ingredient_name'><span class='name'>サラダ油</span></div>
<div class='ingredient_quantity amount'>大さじ1</div>
</div>
<div class='ingredient_row'>
<div class='ingredient_spacer'>
</div>
</div>
</div>
</div>
</div>build()メソッドとiterate()メソッド
上記のコードでは、Parser.data(contentText).from('開始位置’).to('終了位置’).build()と記述しました。
build()メソッドと同様によく使うのが、iterate()メソッドです。build()メソッドが「条件に該当した最初の1回のみを抽出して終了」であるのに対して、iterate()は 「条件に該当する限り繰り返して抽出する」という指定方法になります。 複数要素が返ってくるのでiterate()で記述した場合は配列になります。
ちなみに、id属性はページに同じ値のものが1回しか登場しないはずなので、前パートはどちらの記述方法でも結果は同じということですね。
レシピの材料は同じ形式の記述が複数回登場しているので、最後にbuild()メソッドとiterate()メソッドの違いを見てみましょう。
function Scraping() {
const url = "https://cookpad.com/recipe/7018658";
const contentText = UrlFetchApp.fetch(url).getContentText('utf-8');
try{
var ingredients = Parser.data(contentText).from('<span class=\'name\'>').to('</span>').iterate().map(function(value){
return OmitLink(value.replace('■',''));
})
}catch (e) {
console.log("エラーになりました");
}
console.log(ingredients);
}
function OmitLink(text){
if(text.match('<a')){
return Parser.data(text).from('>').to('</a>').build();
}else {
return text;
}
} <span class='name'>■はんぺん</span>
[ '<span class=\'name\'>■はんぺん</span>',
'<span class=\'name\'>■砂糖</span>',
'<span class=\'name\'><a class="cookdict_ingredient_link" href="/cooking_basics/search/%E3%81%BF%E3%82%8A%E3%82%93">■みりん</a>\n</span>',
'<span class=\'name\'>■日本酒</span>',
'<span class=\'name\'>■しょうゆ</span>',
'<span class=\'name\'>■卵</span>',
'<span class=\'name\'>サラダ油</span>' ]build()の場合は「はんぺん」のみでしたが、iterate()で記述するとすべての食材を抽出することができました。なぜかみりんだけリンクが入ってますね。
状況に応じて使い分けてみてください!
まとめ
・getContentTextの使い方は、UrlFetchApp.fetch([url]).getContentText([文字コード])
・getContentTextで取得したテキストの分析にはParserライブラリを使う
・builとiterateを用いて分析対象のhtmlテキストを抽出する
上記を使いこなせば、比較的自由度高くスクレイピングを実行できるはずです。ぜひいろいろ試してみてくださいね。
今回の記事では特定の1ページのスクレイピングでしたが、複数ページ(URL)の連続スクレイピング方法は下記記事で解説しています。
