GASを使ったWebスクレイピング
Google Apps Script(GAS) を使ってWebページの情報をスクレイピングを行う方法をご紹介します。
WebスクレイピングのGASサンプルコード
下記は厚生労働省のホームページから、最新記事を抽出する処理を行うコードです。
※実行にはParserライブラリのインストールが必要です。「Parserライブラリのインストール」で詳細を確認してください。
function myFunction() {
let response = UrlFetchApp.fetch("https://www.mhlw.go.jp/index.html");
let text = response.getContentText("utf-8");
//トップニュースのブロックを抽出
let topic_block = Parser.data(text).from('<ul class="m-listNews m-gridNews__adjust">').to('</ul>').build();
// console.log(topic_block);
//liタグで囲まれている記述(トップニュース)を抽出
let content_block = Parser.data(topic_block).from('<li>').to('</li>').iterate();
// console.log(content_block);
// 記事リスト用の配列変数を宣言
let articleList= new Array();
// aタグに囲まれた記述の回数分タイトル/URLを抽出する
for(article of content_block){
//記事内のURLとタイトルを抽出
let article_url = Parser.data(article).from('<a href="').to('">').build();
// console.log(article_url);
let article_title = Parser.data(article).from('<div class="m-listNews__txt"><span>').to('</span>').build();
// console.log(article_title);
//取得したリンクにドメインが含まれていなかったらhttps://www.mhlw.go.jpを頭に挿入
if(!article_url.match('https:')){
article_url = 'https://www.mhlw.go.jp/' + article_url;
}
// URL・タイトルの組を作成してリストに格納
let articleInfo = [article_url, article_title];
articleList.push(articleInfo);
}
// console.log(articleList);
}GASを使ったWebスクレイピングの概要を紹介した後に、スクリプトの詳細を解説します。
GASを使ったWenスクレイピングの概要
Webスクレイピングとは
Webスクレイピングとは、指定したWebサイト(URL)にアクセスして情報を取得するためのプログラムです。
WebスクレイピングはPython等他の言語を使ったりスクレイピング用のツールを使うこともできますが、GASでもWebスクレイピングを実行することができます。Googleアプリ、特にスプレッドシートと連携したスクレイピングを行う際は非常に便利です。例えば、スプレッドシートからURLを読み込む、取得情報をスプレッドシートに書き出す等の処理を行う場合はGASでの処理を検討してみてください。
GASでWebスクレイピングを行うメリット
GASでWebスクレイピングを行う大きなメリットは以下の点です。
- 環境構築が不要
- トリガー設定で自動実行が簡単
- Googleサービスとの連携が容易
- 初心者が学びやすい言語
環境構築が不要
PythonやRubyはスクレイピング実行や分析用のパッケージが豊富に用意されていたり、実装したいコードのサンプルがネット上で見つかりやすいメリットがある反面、実行環境のセットアップに時間がかかり、初心者が試すにはハードルが高いのも事実です。
一方で、GASはGoogle Workspace(または個人向けGoogle アカウント)さえあれば、Web上で実行できるため、セットアップに時間がかかりません。スクレイピングを試してみたい初心者や、サクッとスクレイピングを実行したい方にとってGASでのWebスクレイピングは非常におすすめです。
実際にこの記事のサンプルコードを見ながら簡単に実行できるはずなので、興味がある方はぜひ試してみてください。
トリガー設定で自動実行が簡単
他の言語で定期的なスクレイピングを行ったり、特定の日時でスクレイピングするプログラムを実行するには、PCを常時起動したりサーバー側での操作が必要になります。
GASはGoogle Workspace上で実行できるプログラムですが、記述したスククリプトを定期的に実行するためにトリガー機能が用意されており、スクレイピングの自動化が非常にやりやすいです。
トリガーに関する機能は下記の記事でも紹介しています。

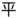 https://tetsuooo.net/gas/497/
https://tetsuooo.net/gas/497/Googleサービスとの連携が容易
スプレッドシート/カレンダー/Gmail等、GASはほとんどのGoogleサービスと連携が可能です。
プログラミングを分析までGAS上で完結することも可能で協力なメリットですが、これらのサービスと連携して、スクレイピング実行結果を日次でスプレッドシートに書き出したり、それをGmailに添付して送るといったこともできます。
初心者が学びやすい言語
環境構築が必要ないので始めやすいというメリットもありながら、GASはjavascriptをベースにした言語で記述方法や関数の種類など、共通した要素が大きくあります。GASで基礎を学びながら、他言語への足掛かりにもできそうです。
スクレイピングをする際の注意点
スクレイピングはやみくもに実行してよいものではありません。他社のWebサイトから取得した情報を自社サービスとして流用する、スクレイピングの実行過程で他社のサーバーに不可をかける、といった法に触れる使い方はせず、便利に使いこなしましょう。
Parserライブラリのインストール
Webスクレイピングによって取得した情報を分析・処理するにはParserライブラリを使う必要が出てくるので、あらかじめライブラリをインストールしておきましょう。
Paserライブラリを利用するにはエディタ左部の「ライブラリ」の「+」ボタンをクリックして、ポップアップ出ててきたボックスの「スクリプトID」欄にParserライブラリのIDを入力、「追加」ボタンをクリックして完了です。
*2022年8月現在の最新のIDでした。アップデートで変更になるので最新のIDを調べて入力してみてください。
1Mc8BthYthXx6CoIz90-JiSzSafVnT6U3t0z_W3hLTAX5ek4w0G_EIrNw
Parserライブラリに関する詳細は下記の記事で詳細を解説しています。

UrlFetchAppでHTTPリクエスト実行
Google Apps Script(GAS)でHTTPリクエストを行うために、UrlFetchAppクラスが用意されています。fetchメソッドを使って引数のURLに対してHTTPリクエストを送ります。
UrlFetchApp.fetch(URL [, パラメータ])
- URL:スクレイピング対象ページのURL
- 戻り値:対象URLのHTTPレスポンス
HTTPResponse.getContentText([charset])
- charset:文字コード(’UTF-8’、’shift-jis’ 等) ※デフォルトは「utf-8」
- 戻り値:HTTP形式の情報が変換された文字列
let response = UrlFetchApp.fetch("https://www.mhlw.go.jp/index.html");
let text = response.getContentText("utf-8");
console.log(text);console.logで文字の羅列が返ってきたら成功です。
GASでWebページの情報をテキストデータで取得するという操作だけれであればここで終了です。ここから、Parserライブラリを使ってこのテキストデータを取得したい情報に処理していきます。
Paserライブラリで文字列を処理する
Parserライブラリのインストール
Webスクレイピングによって取得した情報を分析・処理するにはParserライブラリを使うことが便利です。
Paserライブラリを利用するにはエディタ左部の「ライブラリ」の「+」ボタンをクリックして、ポップアップ出ててきたボックスの「スクリプトID」欄にParserライブラリのIDを入力、「追加」ボタンをクリックして完了です。
*下記が2024年3月現在の最新のIDでした。アップデートで変更になるので最新のIDを調べて入力してみてください。
1Mc8BthYthXx6CoIz90-JiSzSafVnT6U3t0z_W3hLTAX5ek4w0G_EIrNwParserライブラリに関する詳細は下記の記事で詳細を解説しています。
buildメソッドとiterateメソッド
ここまではページ全体の要素をテキスト情報として取得しただけなので、目的に応じた形に作り替えていきます。
まずは該当部分のMTML記述を確認してください。ブラウザでページにアクセスし「F12をクリック」または「ページ上で右クリック→検証」でデベロッパーツールを開くとソースコードを見ることができます。
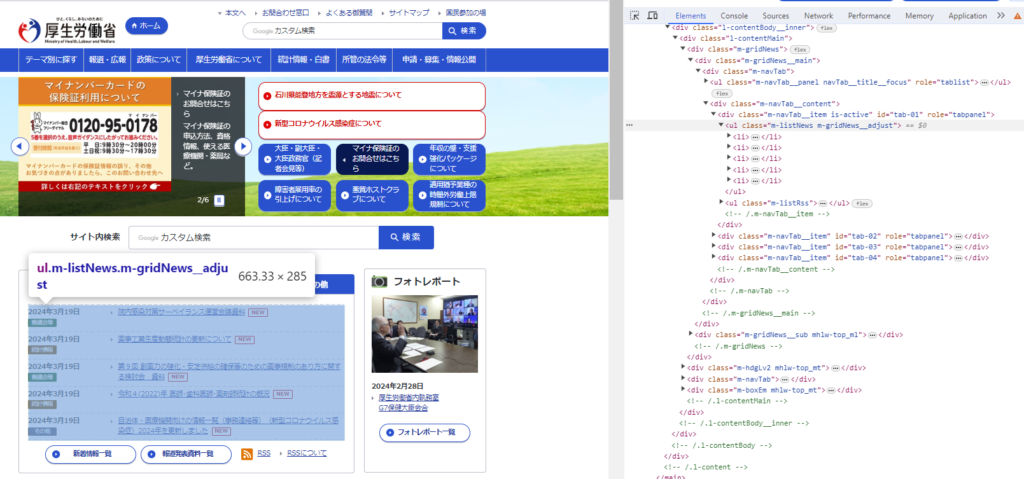
コードを見てみるとトップニュースのブロックはm-listNews m-gridNews__adjustというClass名がついたulタグタグで囲まれています。また、そのulブロックの中で各記事がliタグで囲まれているのが確認できます。このコード仕様に従って処理を記述することで、トップニュースの記事情報を抽出します。
Parser.data(text).from(startText).to(endText).build()
Parser.data(text).from(startText).to(endText).iterate()
- text:処理対象の文字列
- startText:抽出開始位置となる文字列
- endText:抽出終了位置となる文字列
今回はclass属性の名前で指定するのが早いので、開始位置を<ul class="m-listNews m-gridNews__adjust">、終了位置を</ul>としました。
//トップニュースのブロックを抽出
let topic_block = Parser.data(text).from('<ul class="m-listNews m-gridNews__adjust">').to('</ul>').build();
console.log(topic_block);<li><a href="/stf/newpage_38896.html">
<div class="m-listNews__ttl"><time class="m-listNews__date" datetime="2024-03-19">2024年3月19日</time>
<em class="m-listNews__label"><span class="m-label--02">審議会等</span></em></div>
<div class="m-listNews__txt"><span>院内感染対策サーベイランス運営会議資料</span>
<em class="m-icnNew">NEW</em></div></a></li>
<li><a href="https://www.mhlw.go.jp/toukei/list/105-1.html">
<div class="m-listNews__ttl"><time class="m-listNews__date" datetime="2024-03-19">2024年3月19日</time>
<em class="m-listNews__label"><span class="m-label--10">統計情報</span></em></div>
<div class="m-listNews__txt"><span>薬事工業生産動態統計の更新について</span>
<em class="m-icnNew">NEW</em></div></a></li>
<li><a href="/stf/newpage_38892.html">
<div class="m-listNews__ttl"><time class="m-listNews__date" datetime="2024-03-19">2024年3月19日</time>
<em class="m-listNews__label"><span class="m-label--02">審議会等</span></em></div>
<div class="m-listNews__txt"><span>第9回 創薬力の強化・安定供給の確保等のための薬事規制のあり方に関する検討会 資料</span>
<em class="m-icnNew">NEW</em></div></a></li>
<li><a href="https://www.mhlw.go.jp/toukei/saikin/hw/ishi/22/index.html">
<div class="m-listNews__ttl"><time class="m-listNews__date" datetime="2024-03-19">2024年3月19日</time>
<em class="m-listNews__label"><span class="m-label--10">統計情報</span></em></div>
<div class="m-listNews__txt"><span>令和4(2022)年 医師・歯科医師・薬剤師統計の概況</span>
<em class="m-icnNew">NEW</em></div></a></li>
<li><a href="/stf/seisakunitsuite/bunya/0000121431_00452.html">
<div class="m-listNews__ttl"><time class="m-listNews__date" datetime="2024-03-19">2024年3月19日</time>
<em class="m-listNews__label"><span class="m-label--05">その他</span></em></div>
<div class="m-listNews__txt"><span>自治体・医療機関向けの情報一覧(事務連絡等)(新型コロナウイルス感染症)2024年を更新しました</span>
<em class="m-icnNew">NEW</em></div></a></li>さらにここから中の構造を確認すると、1記事がliタグで囲まれていることが分かります。下記のように開始位置と終了位置をそれぞれliタグで囲むと1つの記事単位で抽出できます。
//liタグで囲まれている記述(トップニュース)を抽出
let content_block = Parser.data(topic_block).from('<li>').to('</li>').build();
console.log(content_block);<a href="/stf/newpage_38896.html"> <div class="m-listNews__ttl"><time class="m-listNews__date" datetime="2024-03-19">2024年3月19日</time> <em class="m-listNews__label"><span class="m-label--02">審議会等</span></em></div> <div class="m-listNews__txt"><span>院内感染対策サーベイランス運営会議資料</span> <em class="m-icnNew">NEW</em></div></a>Parserライブラリを使う際、buildメソッドではto~fromで指定された条件の最も最初に合致した文字列を一回のみ抽出、iterateメソッドではto~fromで指定された条件に合致した文字列を合致した回数分抽出して配列に格納してくれます。
上記2つの例ではto~fromに該当する記載がいずれも1か所ずつしかないため、どちらのメソッドでも同じ結果が返ってきますが、次のパートのようにaタグをキーにしてすべてのニュースのリストを取得する場合などはiterateメソッドを使います。
とても便利な機能でスクレイピングを実施すると必ずと言っても良いほど利用するので、ぜひ押さえておきたいですね。
上のilタグに条件に合致するテキストを抽出する際に、iterateメソッドを使った場合は下記のような結果になりました。
//liタグで囲まれている記述(トップニュース)を抽出
let content_block = Parser.data(topic_block).from('<li>').to('</li>').iterate();
console.log(content_block);[ '<a href="/stf/newpage_38896.html">\r\n<div class="m-listNews__ttl"><time class="m-listNews__date" datetime="2024-03-19">2024年3月19日</time>\r\n<em class="m-listNews__label"><span class="m-label--02">審議会等</span></em></div>\r\n<div class="m-listNews__txt"><span>院内感染対策サーベイランス運営会議資料</span>\r\n<em class="m-icnNew">NEW</em></div></a>',
'<a href="https://www.mhlw.go.jp/toukei/list/105-1.html">\r\n<div class="m-listNews__ttl"><time class="m-listNews__date" datetime="2024-03-19">2024年3月19日</time>\r\n<em class="m-listNews__label"><span class="m-label--10">統計情報</span></em></div>\r\n<div class="m-listNews__txt"><span>薬事工業生産動態統計の更新について</span>\r\n<em class="m-icnNew">NEW</em></div></a>',
'<a href="/stf/newpage_38892.html">\r\n<div class="m-listNews__ttl"><time class="m-listNews__date" datetime="2024-03-19">2024年3月19日</time>\r\n<em class="m-listNews__label"><span class="m-label--02">審議会等</span></em></div>\r\n<div class="m-listNews__txt"><span>第9回 創薬力の強化・安定供給の確保等のための薬事規制のあり方に関する検討会 資料</span>\r\n<em class="m-icnNew">NEW</em></div></a>',
'<a href="https://www.mhlw.go.jp/toukei/saikin/hw/ishi/22/index.html">\r\n<div class="m-listNews__ttl"><time class="m-listNews__date" datetime="2024-03-19">2024年3月19日</time>\r\n<em class="m-listNews__label"><span class="m-label--10">統計情報</span></em></div>\r\n<div class="m-listNews__txt"><span>令和4(2022)年 医師・歯科医師・薬剤師統計の概況</span>\r\n<em class="m-icnNew">NEW</em></div></a>',
'<a href="/stf/seisakunitsuite/bunya/0000121431_00452.html">\r\n<div class="m-listNews__ttl"><time class="m-listNews__date" datetime="2024-03-19">2024年3月19日</time>\r\n<em class="m-listNews__label"><span class="m-label--05">その他</span></em></div>\r\n<div class="m-listNews__txt"><span>自治体・医療機関向けの情報一覧(事務連絡等)(新型コロナウイルス感染症)2024年を更新しました</span>\r\n<em class="m-icnNew">NEW</em></div></a>' ]同じ構造のスクリプトが複数並んでいる場合はiterateメソッドのほうが便利ですね。
Paserで取得した文字列を使いやすい形に加工する
ここまで来たら後は、自分が扱いやすい方法でテキストを整形したりエクスポートするだけです。参考として、同じ構造のテキストを繰り返し処理してスプレッドシートに出力するところまでのスクリプトをご紹介します。
前後の文字列構造から抽出したいデータを抜き出す
ここまでで抽出したcontent_blockという変数には複数の記事が同じ構造で格納されています。
一つ目の記事を抽出してみてみると、aタグのhref=以降がディレクトリ以降のURLパス、m-listNews__txtという名前が付いたdivタグ内のspanに囲まれているのが記事名、という構造になっているのが分かります。
この構造を元に、Parserで分解することで得たい情報を抽出します。
let content_block = Parser.data(topic_block).from('<li>').to('</li>').iterate();
console.log(content_block[0]);<a href="/stf/newpage_38896.html"> <div class="m-listNews__ttl"><time class="m-listNews__date" datetime="2024-03-19″>2024年3月19日</time> <em class="m-listNews__label"><span class="m-label–02″>審議会等</span></em></div> <div class="m-listNews__txt"><span>院内感染対策サーベイランス運営会議資料</span> <em class="m-icnNew">NEW</em></div></a>
同じようにParserのメソッドを使うと下記のように記事URLとタイトルを抽出できます。
//記事内のURLとタイトルを抽出
let article_url = Parser.data(content_block[0]).from('<a href="').to('">').build();
console.log(article_url);
let article_title = Parser.data(content_block[0]).from('<div class="m-listNews__txt"><span>').to('</span>').build();
console.log(article_title);/stf/newpage_38896.html
院内感染対策サーベイランス運営会議資料
繰り返し処理で配列に格納
いつくか方法はありますが、for(element of array){・・・}は配列の要素数分の反復処理、かつelementをarray要素の値として扱えるので便利です。
今回の場合、遷移先のリンクはドメインが入っているものと正規のURLで指定されているものがあるので、下記のサンプルではURLのフォーマットによって正規のURLに変換するような処理を入れています。
// 記事リスト用の配列変数を宣言
let articleList= new Array();
// aタグに囲まれた記述の回数分タイトル/URLを抽出する
for(article of content_block){
//記事内のURLとタイトルを抽出
let article_url = Parser.data(article).from('<a href="').to('">').build();
// console.log(article_url);
let article_title = Parser.data(article).from('<div class="m-listNews__txt"><span>').to('</span>').build();
// console.log(article_title);
//取得したリンクにドメインが含まれていなかったらhttps://www.mhlw.go.jpを頭に挿入
if(!article_url.match('https:')){
article_url = 'https://www.mhlw.go.jp/' + article_url;
}
// URL・タイトルの組を作成してリストに格納
let articleInfo = [article_url, article_title];
articleList.push(articleInfo);
}[ 'https://www.mhlw.go.jp/toukei/list/105-1.html’,
'薬事工業生産動態統計の更新について’ ],
[ 'https://www.mhlw.go.jp//stf/newpage_38892.html’,
'第9回 創薬力の強化・安定供給の確保等のための薬事規制のあり方に関する検討会 資料’ ],
[ 'https://www.mhlw.go.jp/toukei/saikin/hw/ishi/22/index.html’,
'令和4(2022)年 医師・歯科医師・薬剤師統計の概況’ ],
[ 'https://www.mhlw.go.jp//stf/seisakunitsuite/bunya/0000121431_00452.html’,
'自治体・医療機関向けの情報一覧(事務連絡等)(新型コロナウイルス感染症)2024年を更新しました’ ] ]
うまく記事のURLとタイトルの組のリストができました。
まとめ
厚生労働省のサイトをGoogle Apps Script(GAS)を使ってスクレイピングし、Parserライブラリを使って、ニュース記事のURLとタイトルを取得する方法について解説しました。
その他のGASスクレイピングに関する解説記事はこちらです。ぜひ参考にしてみてください。

